
В своей недавней статье «Очистка органической выдачи Яндекса от примесей» я упоминал о таком виде примеси как Свежие результаты, в среде SEO-специалистов носящей название «быстроботовской» примеси.
Идентификация относится ли конкретный документ в выдаче Яндекса к быстроботовской примеси, бывает очень полезна при решении аналитических задач. Дело в том, что документы, индексируемые быстроботом и попадающие в выдачу в течение короткого времени, ранжируются иначе, чем документы из основного индекса, и поэтому выдачу от них необходимо очищать при анализе основного алгоритма.
Тогда я рекомендовал идентифицировать быстроботовскую примесь по наличию специальных меток свежести документа («N минут назад», «N часов назад», «вчера», «позавчера» или просто дата не старше 3-4-х дней). Но похоже, подобная метка не является необходимым признаком документа, проиндексированного быстроботом.
Поясню на примере. Так, например, на момент написания статьи в индексе Яндекса присутствует следующий документ без специальной метки свежести в сниппете:
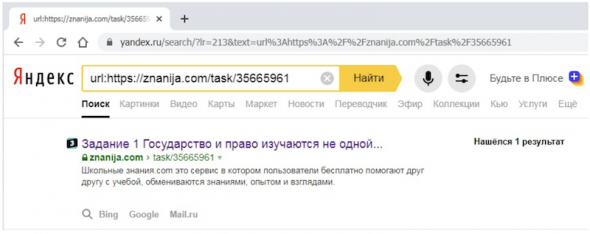
Однако, если мы заглянем в сохраненную копию, то увидим, что документ был проиндексирован через 3 минуты после его появления на сайте (судя по индикации времени, прошедшего с момента публикации пользователем этого материала):
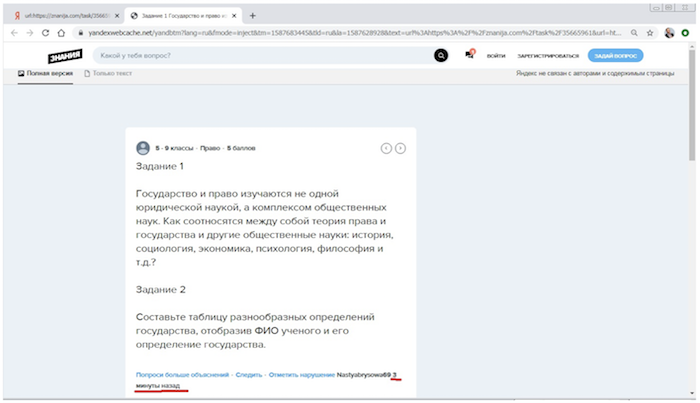
Так быстро после появления документы могут с большой вероятностью попасть в индекс через быстроботовскую примесь. Однако, как уже было сказано выше, метка свежести, характерная для этой примеси, в сниппете данного документа отсутствует.
Изучая поведение документов из быстроботовской примеси, я заметил одну интересную особенность. В отличие от документов из основного индекса, быстроботовские документы показываются в выдаче по запросу, состоящему из связки текстового запроса и документного оператора даже в том случае, когда документ нерелевантен текстовому запросу из этой связки.
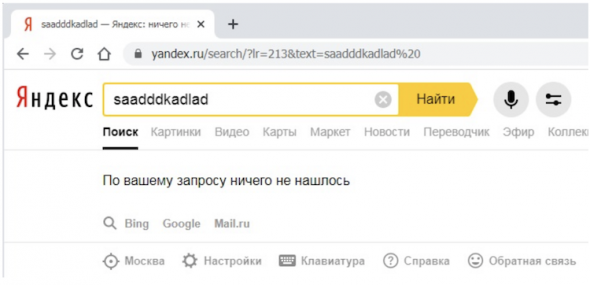
Например, возьмем текстовый запрос в виде абракадабры, выдача по которому пуста:
И добавим к этому текстовому запросу документный оператор url: с адресом рассматриваемого документа в качестве значения. Вопреки логике этот документ показывается в выдаче:
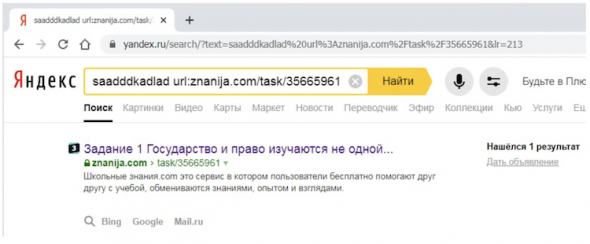
Причем, расширив выдачу на весь сайт с помощью документного оператора site:, мы увидим, что в выдаче в подавляющем большинстве находятся документы с быстроботовской меткой в сниппете.
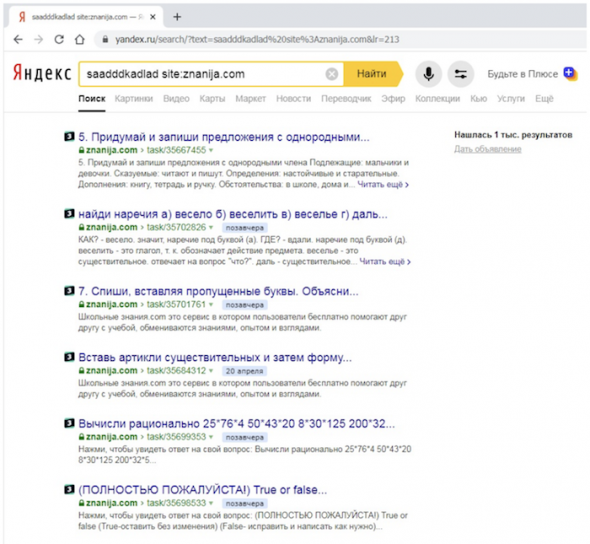
А в сохраненных копиях тех, у кого эта метка отсутствует, наблюдаются признаки того, что документ проиндексирован быстроботом.
Таким образом, можно с определенной долей уверенности утверждать, что подобным способом мы можем проверять документ без быстроботовской метки в сниппете на предмет того, проиндексирован ли он быстроботом. Как правило, это срабатывает на документах трех-четырехдневной давности. Настоятельно рекомендую делать перепроверку с использованием нескольких достаточно сильно отличающихся друг от друга вариантов абракадабр. Дело в том, что некоторые абракадабры Яндекс интерпретирует как опечатки и пытается подобрать варианты замены, не предупреждая об этом пользователя, и в этом случае можно получить ложноположительные срабатывания метода.
Интересно, что добавление к текстовому запросу в рассматриваемой связке операторов группы «Морфология и поисковый контекст» + («плюс» – поиск документов, в которых обязательно присутствует выделенное слово) или «» («кавычки» – поиск по цитате), чудесный эффект быстроботовской примеси пропадает:
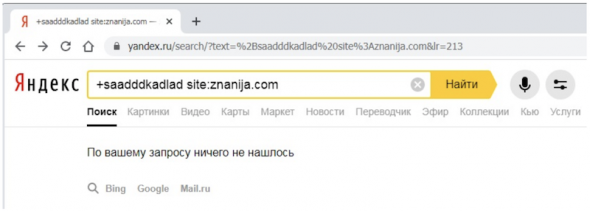
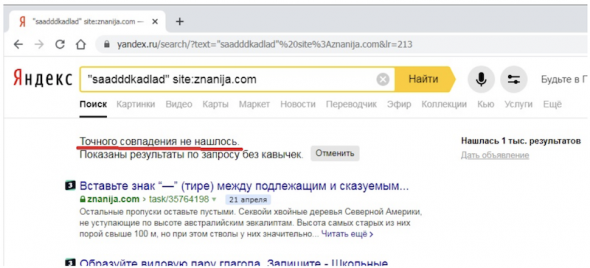
Воспользуемся этим фактом, чтобы убедиться в том, что сохраненная копия для документа, который рассматривался в первом примере, совпадает с той, что находится в индексе (ведь может быть иначе, о чем я писал в своей статье «Сохраненные копии страниц – это не то, что находится в индексе»).
Не мешало бы это проверить, ведь именно по сохраненной копии страницы мы делали предположение о быстроботном характере ее индексации. По точной фразе их сохраненной копии о времени публикации сообщения рассматриваемая страница находится:
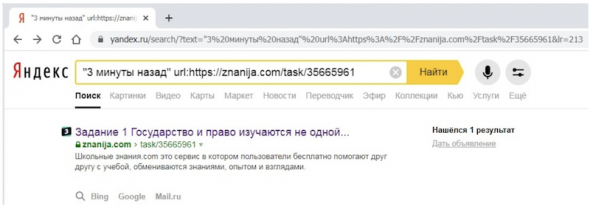
А значит, в индексе действительно та копия, которая показывается как сохраненная. Кстати, для документов из быстроботной примеси я еще не встречал примеров рассинхронизации сохраненной и проиндексированной копий.
Источник